Introduction to Stochastic Calculus
A beginner-friendly introduction to stochastic calculus, focusing on intuition and calculus-based derivations instead of heavy probability theory formalism.
Introduction to Stochastic Calculus
Notation and code for generating visuals are presented in the Appendix.
0. Introduction
This document is a brief introduction to stochastic calculus.
The goal of this blog post is more to focus on the physical intuition and derivation of Brownian motion, which is the foundation of stochastic calculus. I will avoid very technical formalisms such as probability spaces, measure theory, filtrations, etc. in favor of a more informal approach by considering only well-behaved cases. I also try to avoid introducing too many new concepts and vocabulary.
I hope that a wider audience can feel inspired as to how stochastic calculus emerges naturally from the physical world. Then, hopefully, more people can appreciate the beauty and meaning of the mathematics behind it, and decide to dig deeper into the subject.
Applications
Brownian motion and Itô calculus are notable examples of fairly high-level mathematics that are applied to model the real world. Stock prices jiggle erratically, molecules bounce in fluids, and noise partially corrupts signals. Stochastic calculus gives us tools to predict, optimize, and understand these messy systems in a simpified model.
- Physics: Einstein used Brownian motion to prove atoms exist—its jittering matched molecular collisions.
- Finance: Option pricing (e.g., the famous Black-Scholes equation) relies on stochastic differential equations like \(dS = \mu S dt + \sigma S dW\).
- Biology: Random walks model how species spread or neurons fire.
This is just the tip of the iceberg. More and more applications are emerging, notably in machine learning, as Song et al. (2021) have shown in their great paper “Score-Based Generative Modeling through Stochastic Differential Equations”.
They precisely use a stochastic differential equation using Itô calculus to model the evolution of noise over time, which they can then reverse in time to generate new samples. This framework generalizes previous ones and improves performance, allowing for new paths of innovation to be explored.
1. Motivation
Pascal’s triangle gives the number of paths that go either left or right at each step, up to a certain point:
Using 0-indexing, the number of ways to reach the \(k\)-th spot in the \(n\)-th row is \(\binom{n}{k} = \frac{n!}{k!(n-k)!}\). For example, in row 3, there are \(\binom{3}{2} = 3\) ways to hit position 2.
 Code 2D image: All 3 paths for the 2nd position in the 3rd row of Pascal’s triangle
Code 2D image: All 3 paths for the 2nd position in the 3rd row of Pascal’s triangle
Why care? This setup powers the binomial distribution, which models repeated trials with two outcomes—win or lose, heads or tails. Think of:
- A basketball player shooting free throws with probability \(p\) of success and \(q = 1 - p\) of failure.
- A gambler betting on dice rolls.
Pascal’s triangle tells us there are \(\binom{n}{k}\) ways to get \(k\) wins in \(n\) trials. If the trials are independent, we can use the multiplication rule for probabilities:
Note that the independence assumption is strong. Real life isn’t always so clean—winning streaks in games often tie to mentality or momentum, not just chance. Keep in mind that this model can and will be inaccurate, especially visibile for very long streaks in phenomena like stock prices or sports. However, in more common scenarios, it usually approximates reality well.
For one sequence with \(k\) wins (probability \(p\) each) and \(n - k\) losses (probability \(q\) each), the probability is \(p^k q^{n-k}\). Multiply by the number of ways to arrange those wins, and we get:
This is the binomial distribution—great for discrete setups. Now, let’s zoom out. The real world often involves continuous processes, like:
- The motion of a falling object,
- Gas diffusing through a room,
- Stock prices jumping around,
- Molecules colliding in a liquid.
For these, the binomial model gets messy as trials pile up. Calculus, with its focus on continuous change, feels more natural. In the continuous case:
Points and sums (discrete tools) lead to infinities. We need intervals and integrals instead.
2. From Discrete Steps to Continuous Limits
It’s actually known what happens to the binomial distribution as it becomes continuous. But what does that conversion mean mathematically? Let’s dig in with examples and then formalize it.
In calculus, going from discrete to continuous means shrinking step sizes and cranking up the number of steps. For an interval \([a, b]\), we:
- Split it into \(n\) chunks of size \(h = \frac{b - a}{n}\),
- Sum up contributions (like a Riemann sum),
- Let \(n \to \infty\) and \(h \to 0\), landing on an integral.
Can we adapt this to the binomial distribution? Let’s try.
Picture the \(n\)-th row of Pascal’s triangle as a random walk: at each of \(n\) steps, we move \(+1\) (a win) or \(-1\) (a loss).
We’ll set the probabability of winning as \(p = 0.5\) as a first example since it’s symmetric, making each direction equally likely and simpler to work with.
The number of ways to get \(k\) wins (and \(n - k\) losses) is \(\binom{n}{k}\). Let’s try to plot this for a different values \(n\) over \(k\). (The code can be found in the Appendix.)
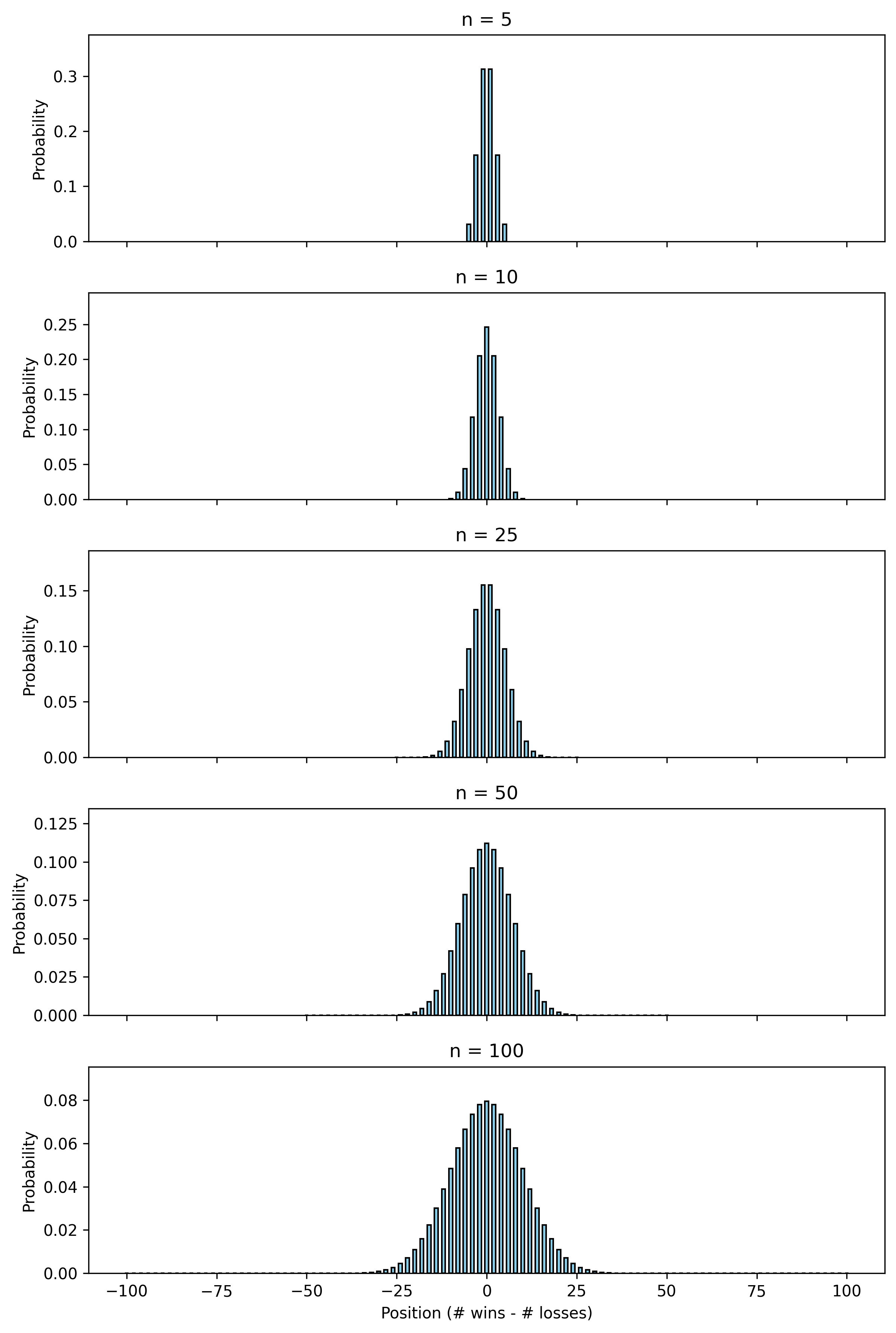 Code 2D image: Binomial distribution plots for n=5,10,25,50,100
Code 2D image: Binomial distribution plots for n=5,10,25,50,100
That looks awfully familiar, doesn’t it? It’s a bell curve, so naturally, we might guess that the limit is a normal distribution (aka Gaussian distribution).
Where does such a normal distribution arise from? The answer lies in the Central Limit Theorem, which states that the sum of a large number of independent random variables will be approximately normally distributed. So where’s the sum happening here? Let’s proceed to formalizing our intuition.
To accomplish this, let’s define a random variable for a single step as:
Here, \(X(t)\) will encode our displacement at the \(t\)-th step where \(t \in \{1,\dots,n\}\) is an indexing parameter. As before, we assume that \(X(t_1)\) is independent of \(X(t_2)\) for \(t_1 \ne t_2 \). At each step \(t\), \(X(t)\) has mean \(0\) and variance \(1\).
Then, the overall displacement \(S(n)\) is:
So there it is! The central limit theorem states more precisely that given \(n\) independent and identically distributed random variables \(X_1, X_2, \dots, X_n\) with mean \(\mu\) and variance \(\sigma^2\), we have:
This is precisely what we need. As we take \(n \to \infty\), we have that
such that
which is our desired limit. We have shown that a “continuous binomial distribution” is in fact a normal distribution.
Here are some very nice 3D animations of sample paths with the distribution evolving over the number of steps:
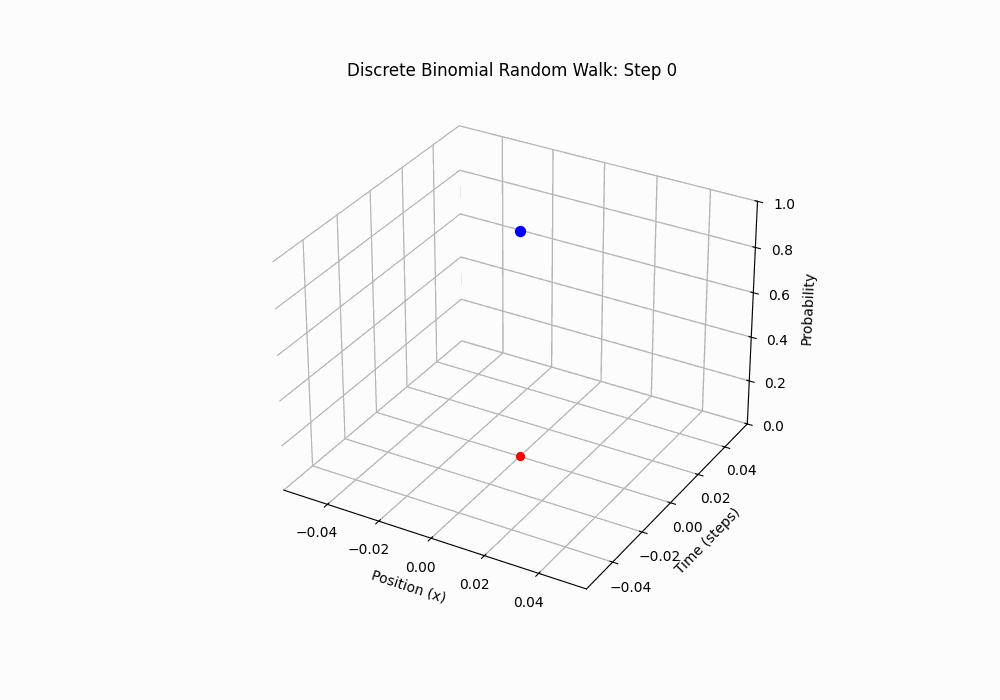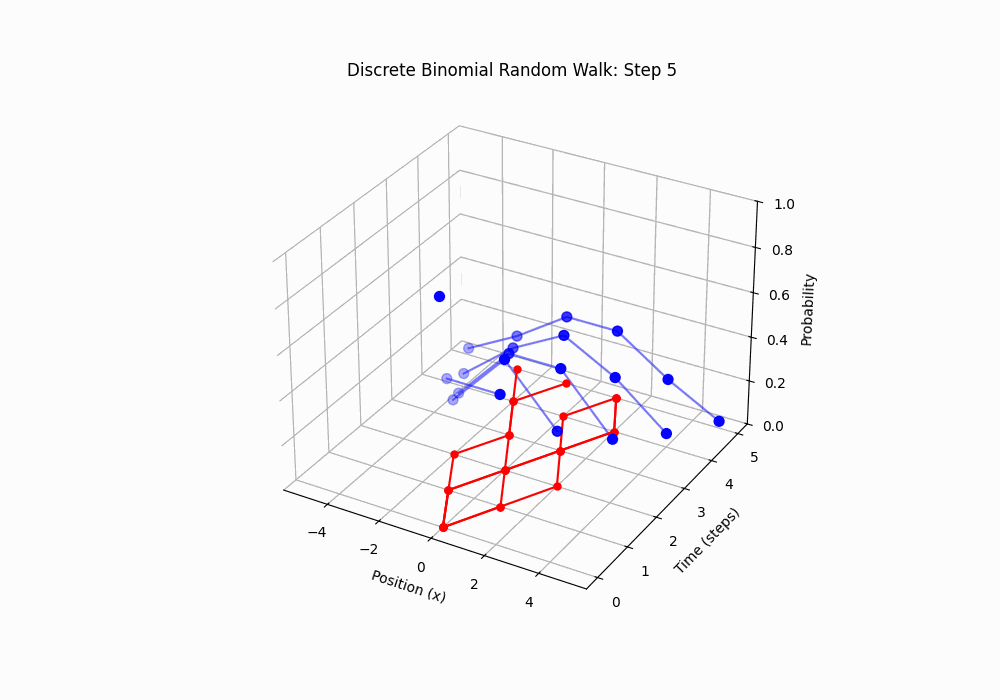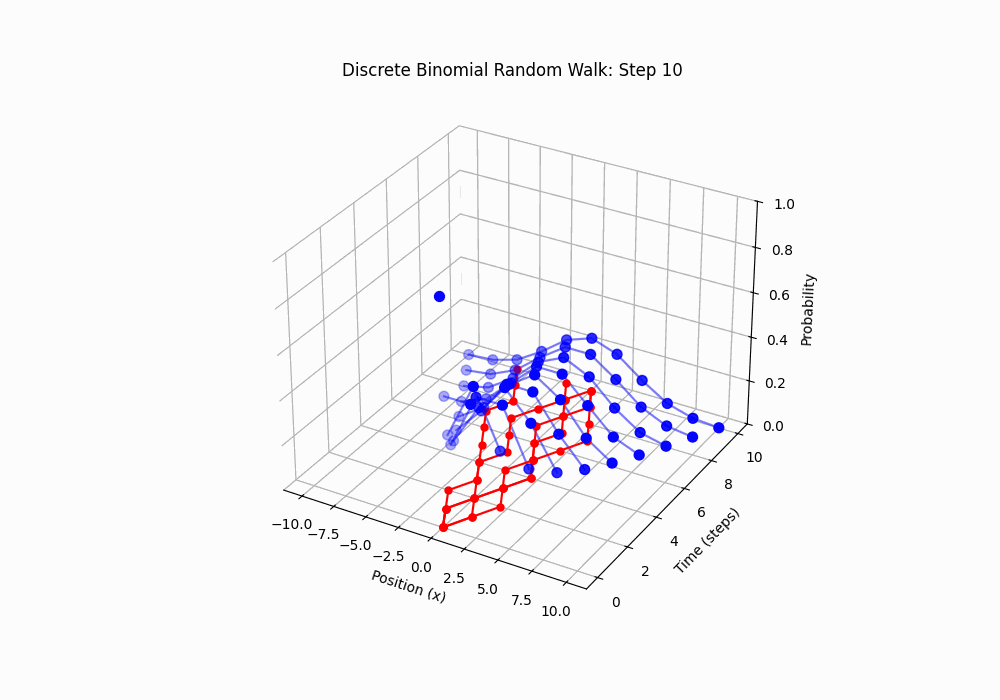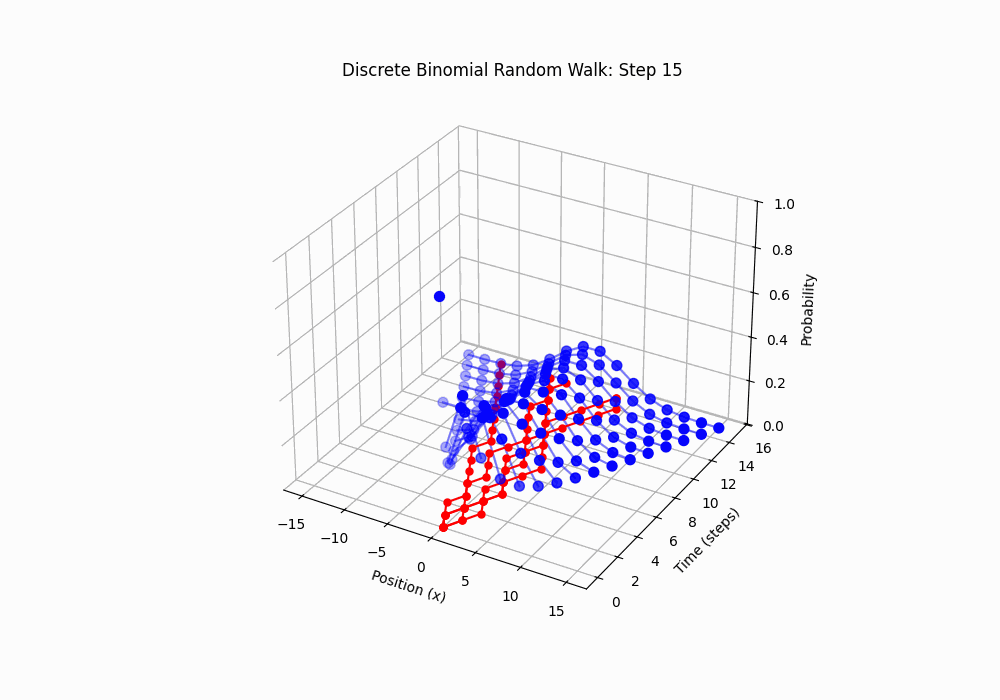 Code 3D animation: Discrete Random Walk, 15 steps
Code 3D animation: Discrete Random Walk, 15 steps
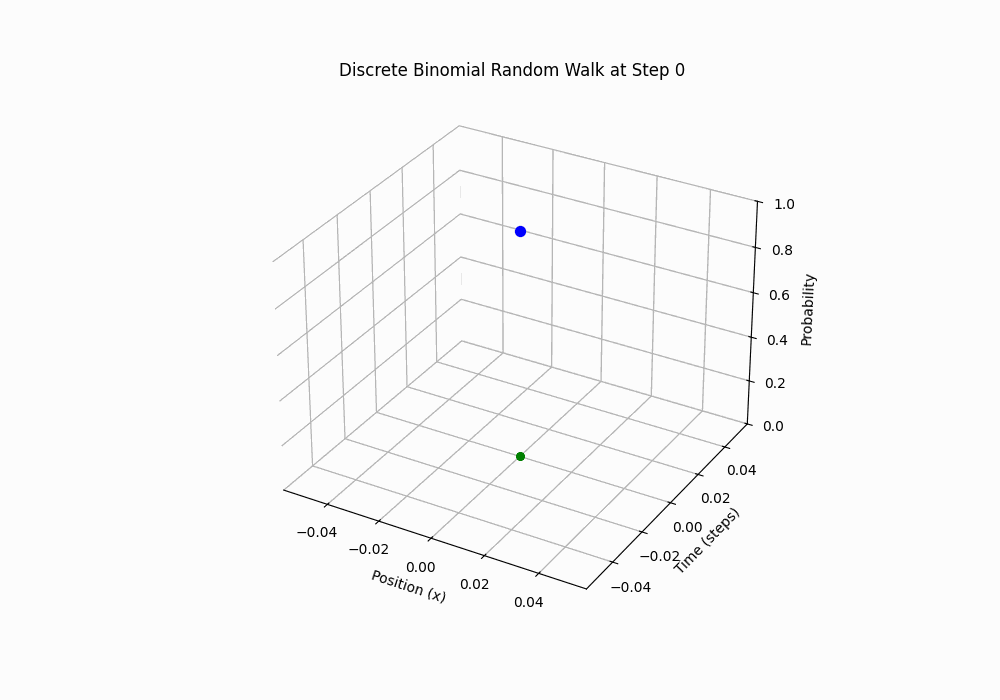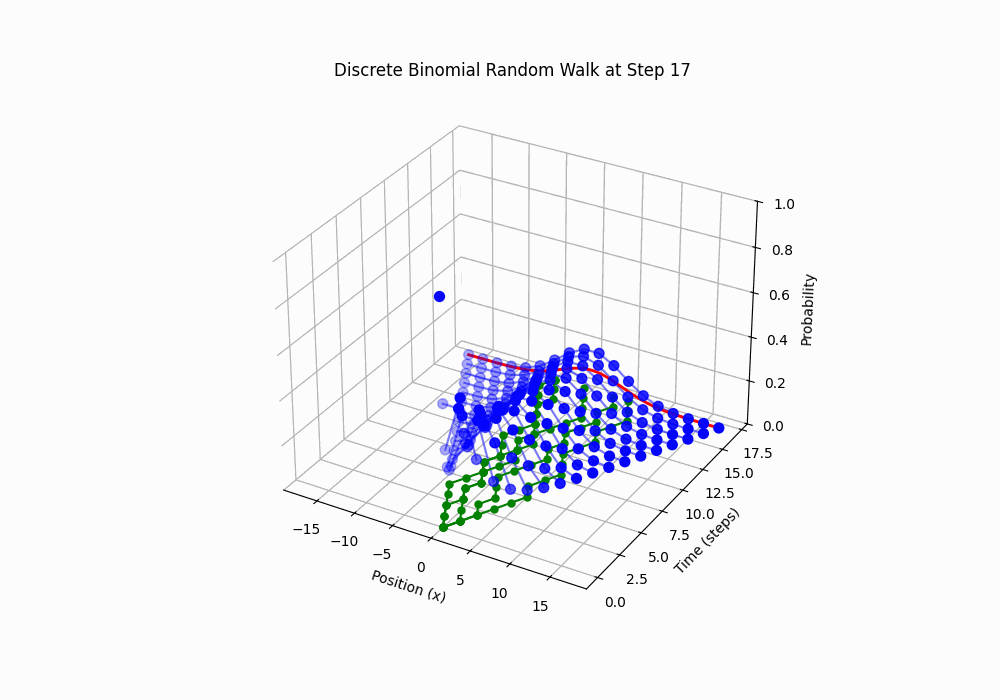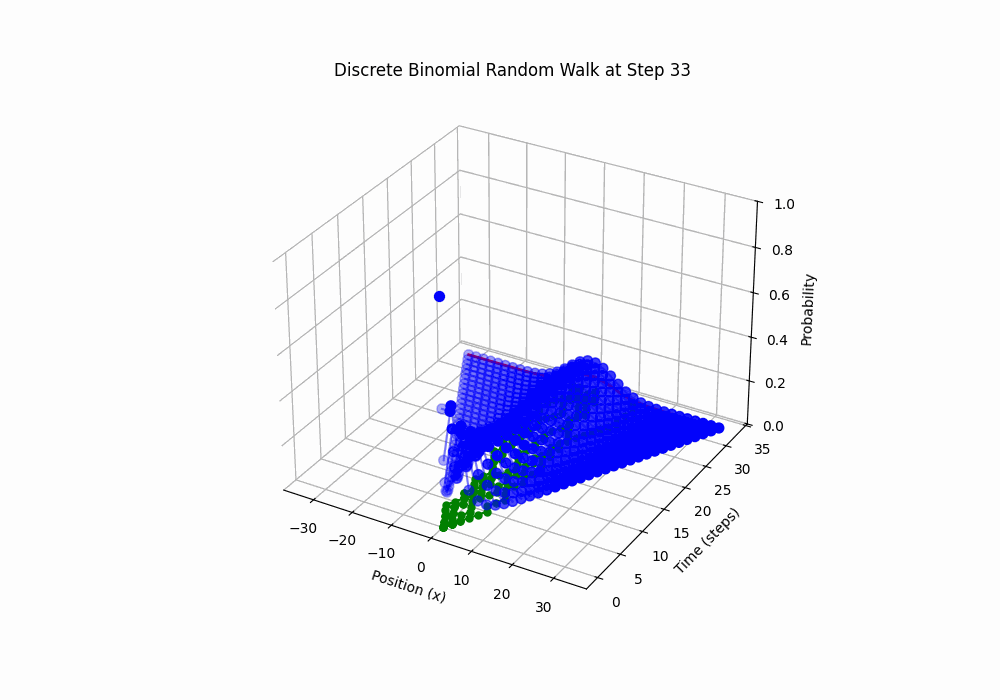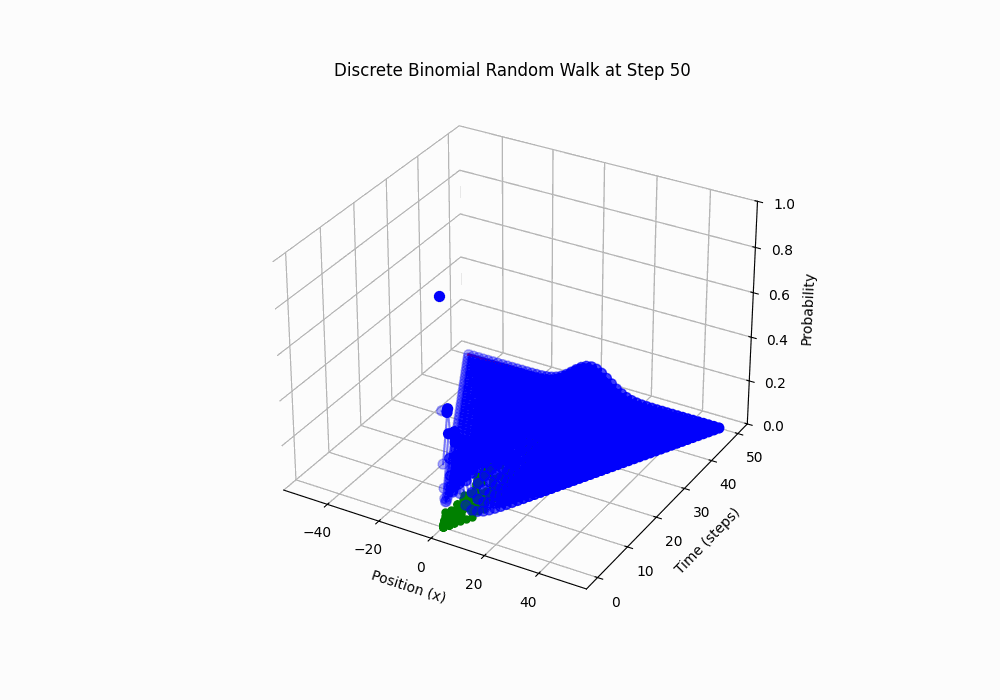 Code 3D Animation: Discrete Random Walk, 100 steps over 5 seconds
Code 3D Animation: Discrete Random Walk, 100 steps over 5 seconds
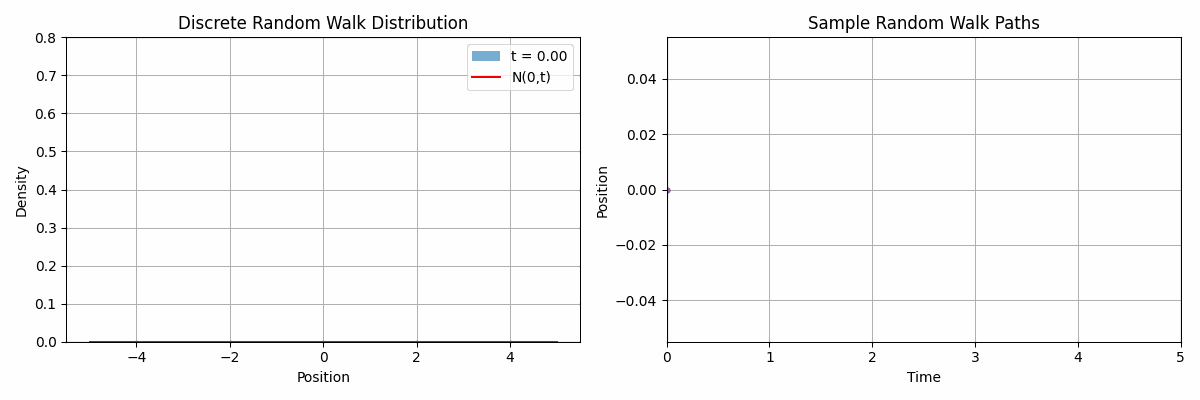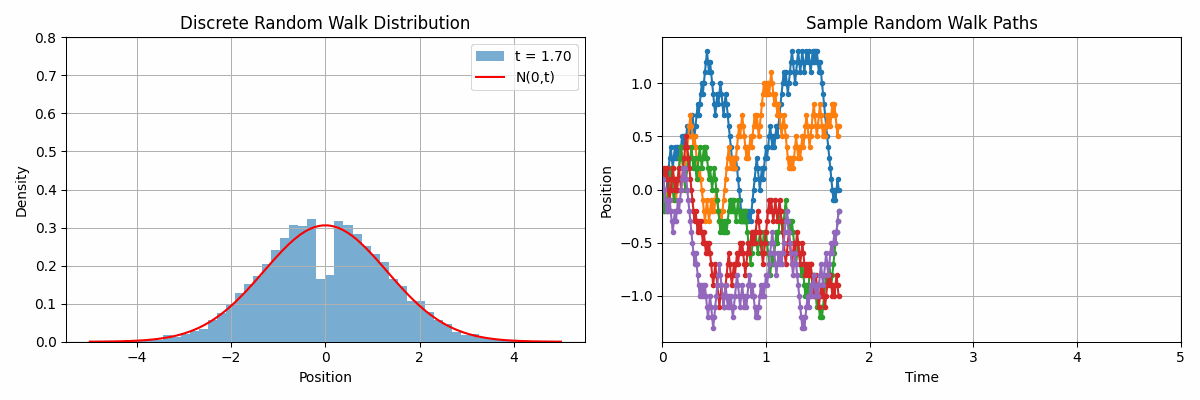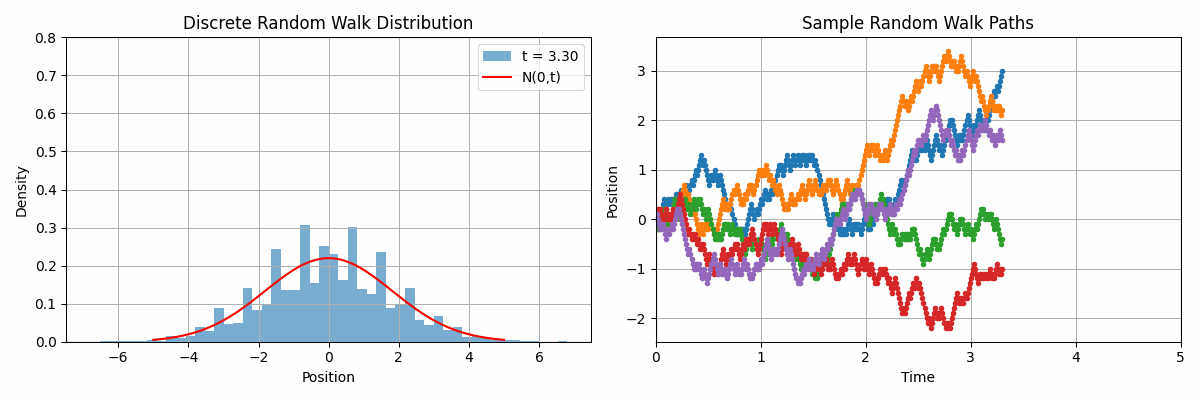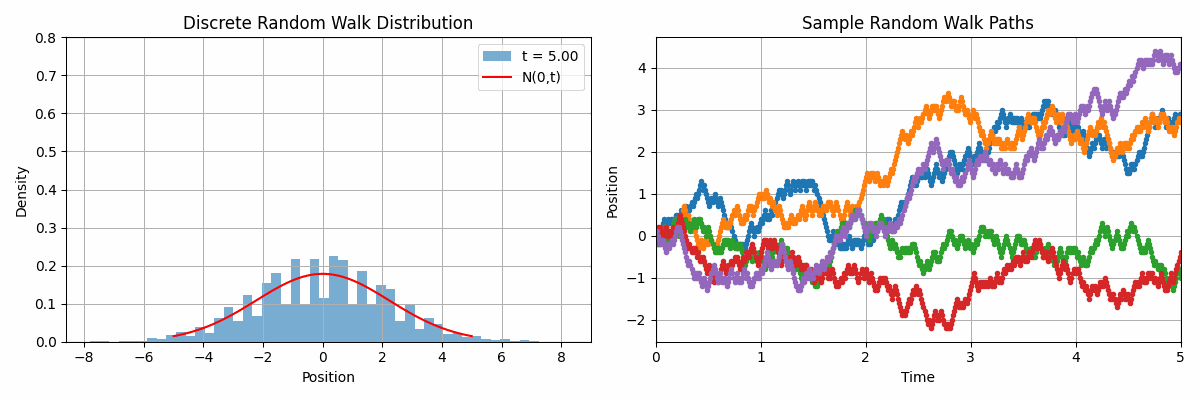 Code 2D animation: Normal distribution approximation by discrete random walks
Code 2D animation: Normal distribution approximation by discrete random walks
3. Defining Brownian motion (Wiener process)
Let’s consider a scenario faced by Scottish botanist Robert Brown in the 1820s. Imagine a small particle, like dust or pollen, floating on a body of water.
Brown realized that its movement was surprisingly erratic. It seemed like the small-scale nature of the setup resulted in such sensitivity to fluctuations, so much is that the real movement from external forces would completely overtake the previous one. Hence, in a simplified mathematical model we scale consider the events at different times as independent.
In addition, there is positional symmetry: the average position of the particle at time \(t\) seemed to float approximately around the origin.
Motivated by these observations as well as our previous intuition on continuous random walks, let’s first think about a simplified model for 1-dimensional discrete case. We’ll list some properties that a continuous random walk should have.
- Starting Point: As a mathematical convenience, we position our coordinate system to set the starting point of the walk to be zero.
- Positional Symmetry: The walk has no directional bias. For each step, the expected displacement is zero, such that the overall expected displacement is also zero.
- Independence: Steps at different times are independent. The displacement between two different intervals of time is independent.
- Continuity: The walk is continuous, with no jumps or gaps.
- Normality: As we established by taking discrete random walks in the continuous limit, the distribution of positions at any given time should be normal.
So let’s write this mathematically. Such a random variable is usually denoted either by \(B_t\) for “Brownian motion”, which is the physical phenomenon, or \(W_t\) for “Wiener process”, in honor of the mathematician Norbert Wiener who developed a lot of its early theory.
I will use \(W(t)\) to emphasize its dependence on \(t\).
Let \(W(t)\) be the position of the Brownian motion at time \(t\), and let \(\Delta W(t_1,t_2)\) be the displacement of the Brownian motion from time \(t_1\) to time \(t_2\).
Note that, unlike the discrete case, we cannot consider a single increment and have a single index \(t\) for displacements as we did with \(X(t)\). As mentioned, the continuous case requires considering intervals instead of single steps.
Then, we write some properties of Brownian motion:
- \(W(0)=0\) almost surely
- $W(t)~N(0,t)$
- With the first condition, this is often written equivalently as \(\Delta W(s,t)\sim N(0,t-s)\) for all \(s \ne t\)
- \(\Delta W(t_1,t_2)\) is independent of \(\Delta W(t_2,t_3)\) for arbitrary distinct \(t_1 < t_2 \le t_3\)
We can straightforwardly use these conditions are enough to find
- \(E[W(t)]=0\) for all \(t\)
- \(Var(W(t))=t\) for all \(t\)
This is analogous to the discrete case.
But it also turns out that these conditions are sufficient to prove continuity, although it’s more involved:
- The sample path \(t \mapsto W(t) \) is almost surely uniformly Hölder continuous for each exponent \(\gamma < \frac{1}{2}\), but is nowhere Hölder continuous for \(\gamma >= \frac{1}{2}\). p.30,33 of source
- In particular, a sample path \(t \mapsto W(t)\) is almost surely nowhere differentiable.
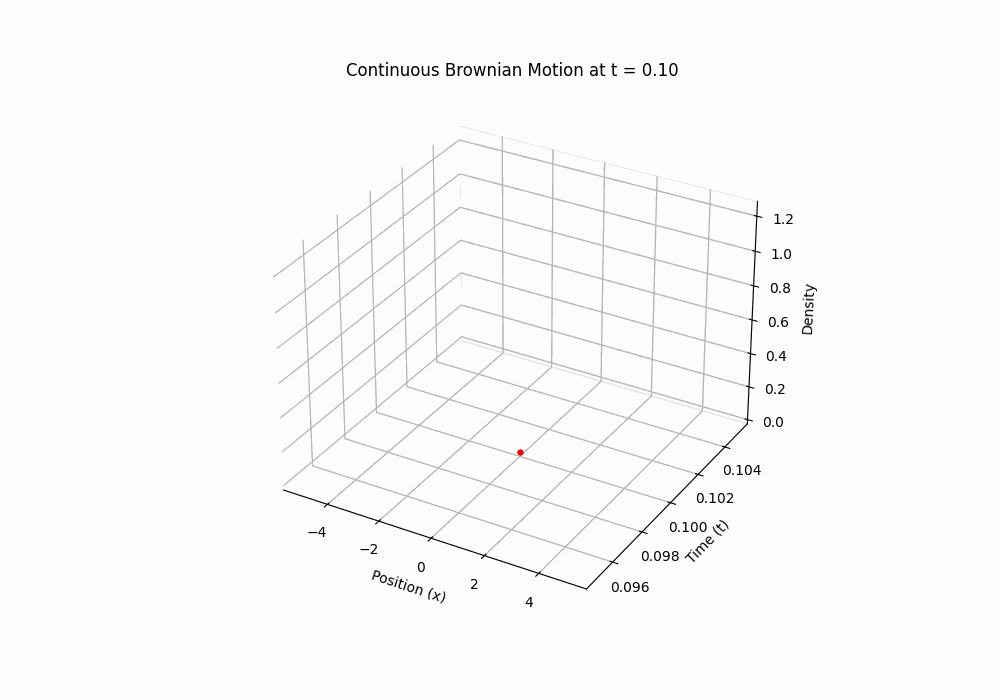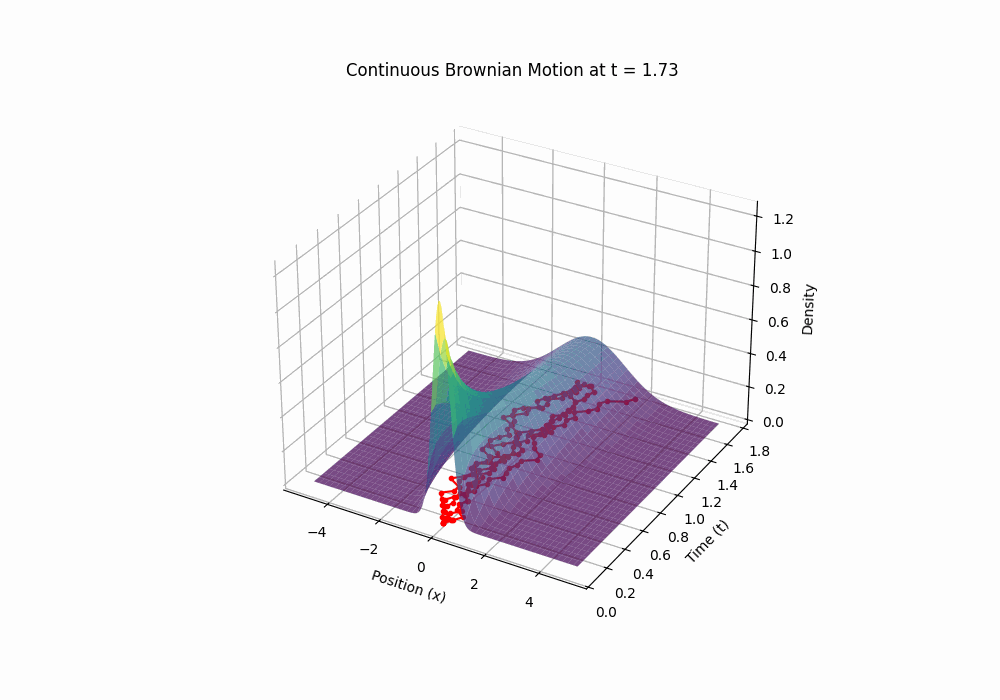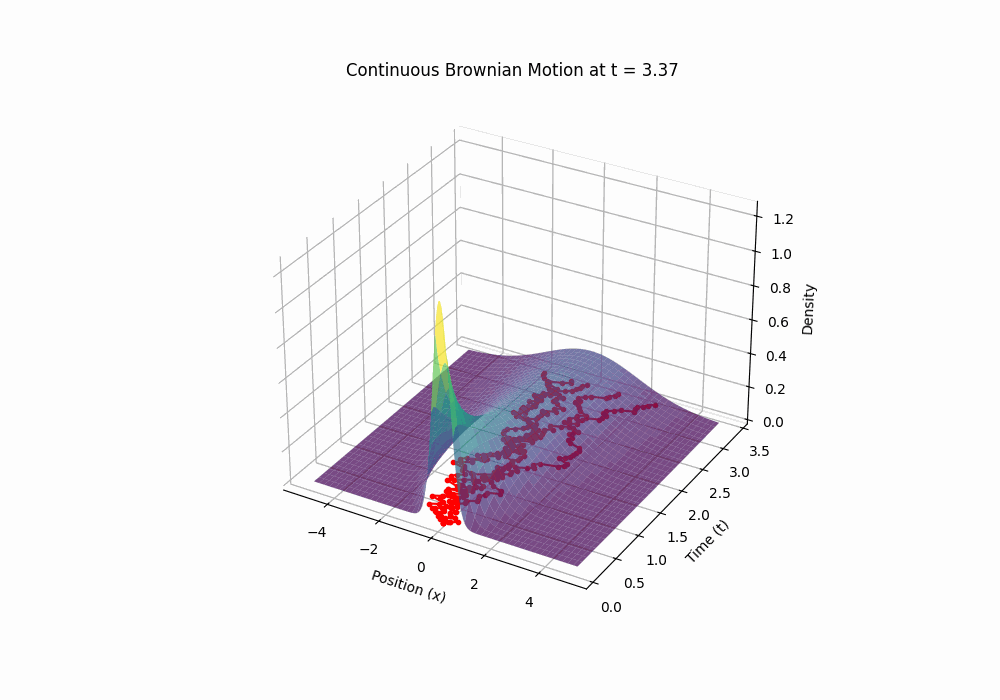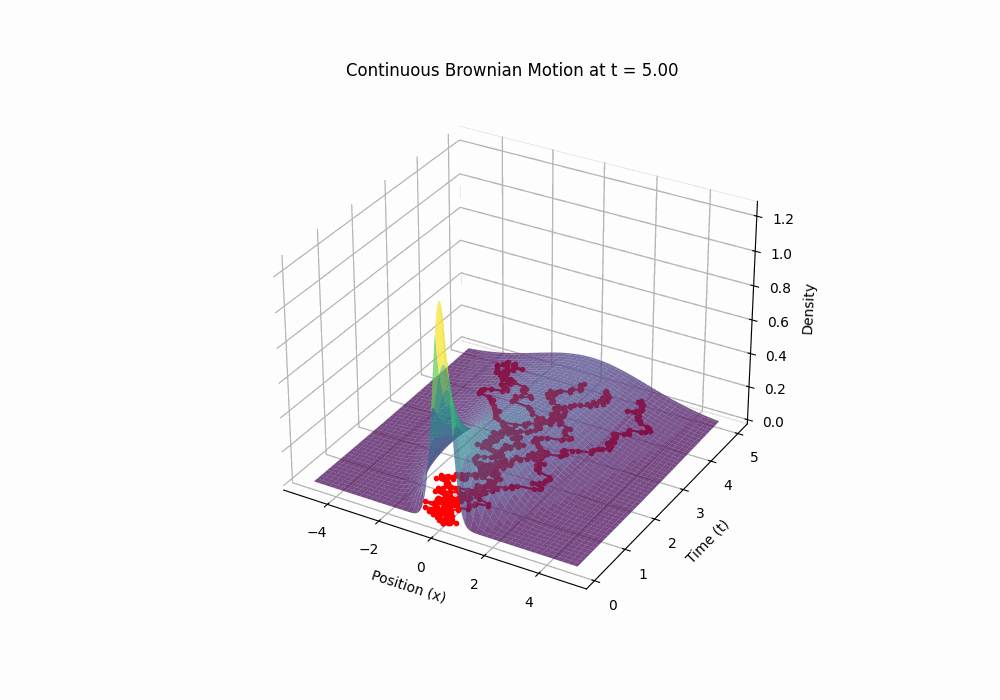
So, \(W(t)\) is our mathematical model for Brownian motion: a continuous, random, zero-mean process with variance proportional to time. It’s wild—it’s globally somewhat predictable yet locally completely unpredictable. A plot of W(t) looks like a jagged mess, but it’s got structure under the hood. (You can generate one yourself with the code in Appendix.)
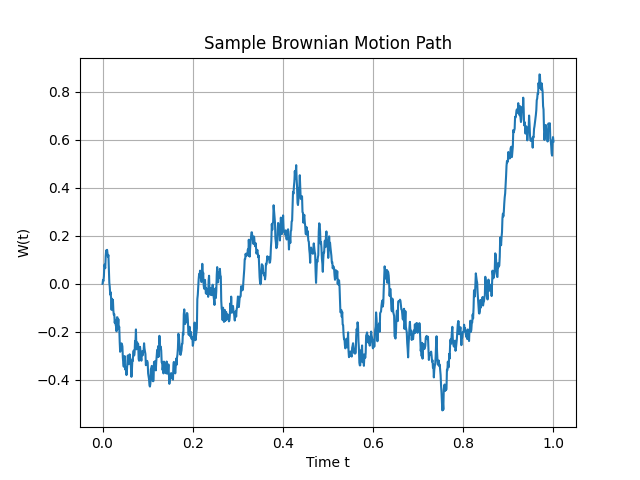 Code 2D image: Sample Brownian motion path
Code 2D image: Sample Brownian motion path
Code 3D animation: Brownian motion with evolving distribution
Now, let’s take this beast and do something useful with it.
4. Itô Calculus
Brownian motion \(W(t)\) is continuous but so irregular that it’s nowhere differentiable. To see why, consider the rate of change over a small interval \(dt\):
Since \(\Delta W(t, t + dt) \sim N(0, dt) = \sqrt{dt} \, N(0, 1)\):
As \(dt \to 0\), \(\frac{1}{\sqrt{dt}}\) grows without bound, and the expression becomes dominated by random fluctuations—it doesn’t converge to a finite derivative. This rules out standard calculus for handling Brownian motion, but we still need a way to work with processes driven by it, like stock prices or particle diffusion.
In the 1940s, Kiyosi Itô developed a framework to address this: Itô calculus. Rather than forcing Brownian motion into the rules of regular calculus, Itô built a new system tailored to its random nature, forming the foundation of stochastic calculus.
The Increment \(dW\) and Its Properties
Define the small change in Brownian motion over an interval \(dt\):
From Section 3, \(W(t + dt) - W(t) \sim N(0, dt)\), so:
Unlike the deterministic \(dx\) in regular calculus, \(dW\) is random—its magnitude scales with \(\sqrt{dt}\), and its sign depends on a standard normal distribution \(N(0, 1)\). It’s a small but erratic step, with:
- \(E[dW] = 0\),
- \(Var(dW) = E[(dW)^2] = dt\).
Now consider \((dW)^2\). Its expected value is \(dt\), but what about its variability? The variance is \(Var[(dW)^2] = 2 dt^2\), which becomes negligible as \(dt \to 0\). This stability allows us to treat \((dW)^2 \approx dt\) in Itô calculus (formally, in the mean-square sense—see the Appendix for details). In contrast to regular calculus, where \((dx)^2\) is too small to matter, \((dW)^2\) is on the same scale as \(dt\), which changes how we handle calculations.
The Itô Integral: Integrating Against Randomness
In regular calculus, \(\int_a^b f(x) \, dx\) approximates the area under a curve by summing rectangles, \(\sum f(x_i) \Delta x\), and taking the limit as \(\Delta x \to 0\). For Brownian motion, we want something like \(\int_0^t f(s) \, dW(s)\), where \(dW(s)\) replaces \(dx\). Here, the steps are random: \(\Delta W(s_i, s_{i+1}) \sim \sqrt{\Delta s} \, N(0, 1)\). We approximate:
over a partition \(s_0, s_1, \dots, s_n\) of \([0, t]\), then let \(n \to \infty\). Unlike a deterministic integral, the result is a random variable, reflecting \(W(t)’s\) randomness. Using \(f(s_i)\) from the left endpoint keeps the integral “non-anticipating”—we only use information up to time \(s_i\), which aligns with the forward-evolving nature of stochastic processes.
Itô’s Lemma: A Chain Rule for Randomness
For a function \(f(t, W(t))\), regular calculus gives:
But Brownian motion’s roughness requires a second-order term. Taylor-expand \(f(t, W(t))\):
As \(dt \to 0\):
- \(dt^2\) and \(dt \, dW\) vanish,
- \((dW)^2 \approx dt\) stays significant.
This leaves:
This is Itô’s Lemma. The extra \(\frac{1}{2} \frac{\partial^2 f}{\partial W^2} dt\) arises because \((dW)^2\) contributes at the \(dt\) scale, capturing the effect of Brownian motion’s curvature.
Since we have the algebraic heuristic \(dW^2 = dt\), we could in some define everything in terms of powers \(dW\) to expand things algebraically and implicitly compute derivative rules.
This is precisely the idea behind my blog post on Automatic Stochastic Differentiation, where we use \(\mathbb{R}[\epsilon]/\epsilon^3\) in a similar fashion to dual numbers \(\mathbb{R}[\epsilon]/\epsilon^2\) for automatic differentiation in deterministic calculus.
If you haven’t already, I highly recommend checking it out.
Example: \(f(W) = W^2\)
Take \(f(t, W(t)) = W^2\):
- \(\frac{\partial f}{\partial t} = 0\),
- \(\frac{\partial f}{\partial W} = 2W\),
- \(\frac{\partial^2 f}{\partial W^2} = 2\).
Then:
Integrate from 0 to \(t\) (with \(W(0) = 0\)):
The \(t\) term matches \(E[W(t)^2] = t\), and the integral is a random component with mean 0, consistent with Brownian motion’s properties.
5. Stochastic Differential Equations
Itô calculus gives us tools—integrals and a chain rule—to handle Brownian motion. Now we can model systems where randomness and trends coexist, using stochastic differential equations (SDEs). Unlike regular differential equations (e.g., \(\frac{dx}{dt} = -kx\)) that describe smooth dynamics, SDEs blend deterministic behavior with stochastic noise, fitting phenomena like stock prices or diffusing particles.
Defining an SDE
Consider a process influenced by both a predictable trend and random fluctuations:
- \(X(t)\): The evolving quantity (e.g., position or price).
- \(a(t, X(t)) \, dt\): The “drift”—the systematic part, scaled by \(dt\).
- \(b(t, X(t)) \, dW(t)\): The “diffusion”—random perturbations from Brownian motion.
Here, \(a\) and \(b\) are functions of time and state, and \(dW(t) = \sqrt{dt} \, N(0, 1)\) brings the noise. Solutions to SDEs aren’t fixed curves but random paths, each run producing a different trajectory with statistical patterns we can study.
Itô’s Lemma Revisited
Itô’s lemma actually applies to a function \(f(t, X(t))\) and its stochastic derivative \(df(t, X(t))\) for a general \(dX(t) = b(t,X(t))dt+\sigma(t,X(t))dW\), and this is done through the linearity of the Itô differential (as seen using the \(\mathbb{R}[\epsilon]/\epsilon^3\) formulation).
Considering that \(dX=O(dW)\), we consider terms up to \(dX^2=O(dW^2)\):
which is the general form typically presented.
Drift and Diffusion
The drift \(a(t, X)\) sets the average direction, like a current pushing a particle. The diffusion \(b(t, X)\) determines the random jitter’s strength. If \(b = 0\), we get a standard ODE; if \(a = 0\), it’s just scaled Brownian motion. Together, they model systems with both structure and uncertainty.
Take a simple case:
- \(\mu\): Constant drift.
- \(\sigma\): Constant noise amplitude.
Starting at \(X(0) = 0\), integrate:
Since \(W(t) \sim N(0, t)\), we have \(X(t) \sim N(\mu t, \sigma^2 t)\)—a process drifting linearly with noise spreading over time. It’s a basic model for things like a stock with steady growth and volatility.
 Code 2D image: Sample SDE path with mu=1.0, sigma=0.5
Code 2D image: Sample SDE path with mu=1.0, sigma=0.5
Geometric Brownian Motion
For systems where changes scale with size—like stock prices or certain physical processes—consider geometric Brownian motion (GBM):
- \(S(t)\): The state (e.g., stock price).
- \(\mu S(t)\): Proportional drift.
- \(\sigma S(t)\): Proportional noise.
The percentage change \(\frac{dS}{S} = \mu \, dt + \sigma \, dW\) has a trend and randomness. To solve, let \(f = \ln S\):
- \(\frac{\partial f}{\partial t} = 0\),
- \(\frac{\partial f}{\partial S} = \frac{1}{S}\),
- \(\frac{\partial^2 f}{\partial S^2} = -\frac{1}{S^2}\).
Using Itô’s lemma:
Integrate from \(0\) to \(t\):
The drift is adjusted by \(-\frac{1}{2} \sigma^2\) due to the second-order effect of noise, and \(\sigma W(t)\) adds random fluctuations. This form underlies the Black-Scholes model in finance.
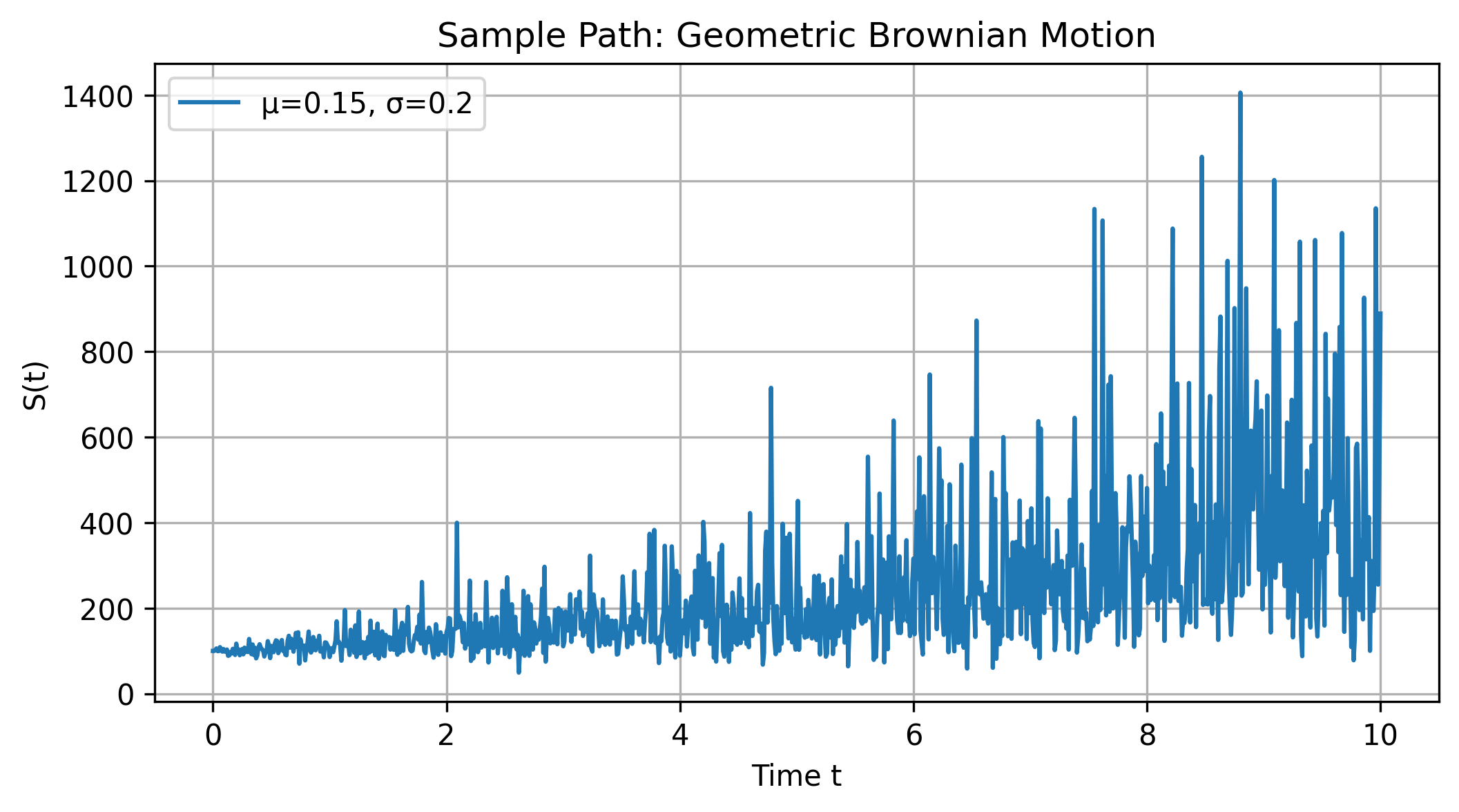 Code 2D image: A sample path of a geometric Brownian motion with parameters μ = 0.15 and σ = 0.2
Code 2D image: A sample path of a geometric Brownian motion with parameters μ = 0.15 and σ = 0.2
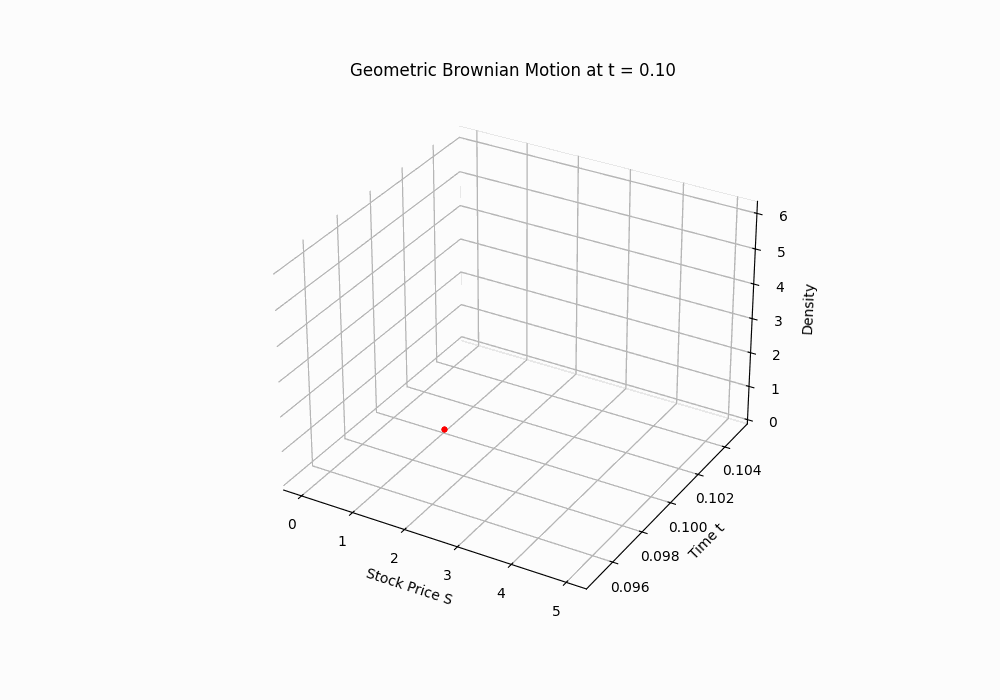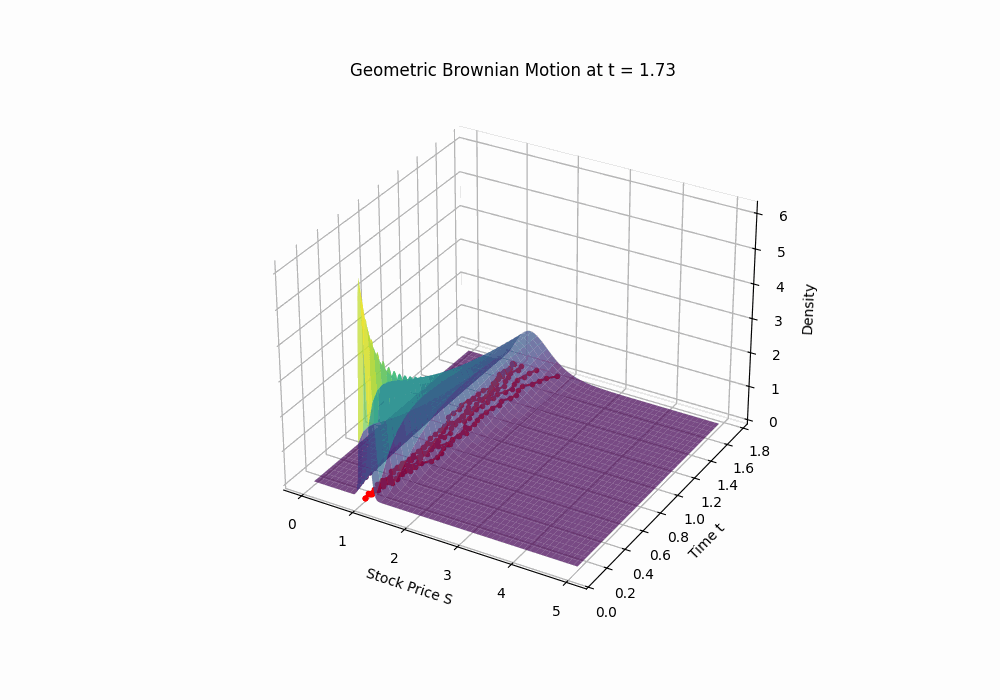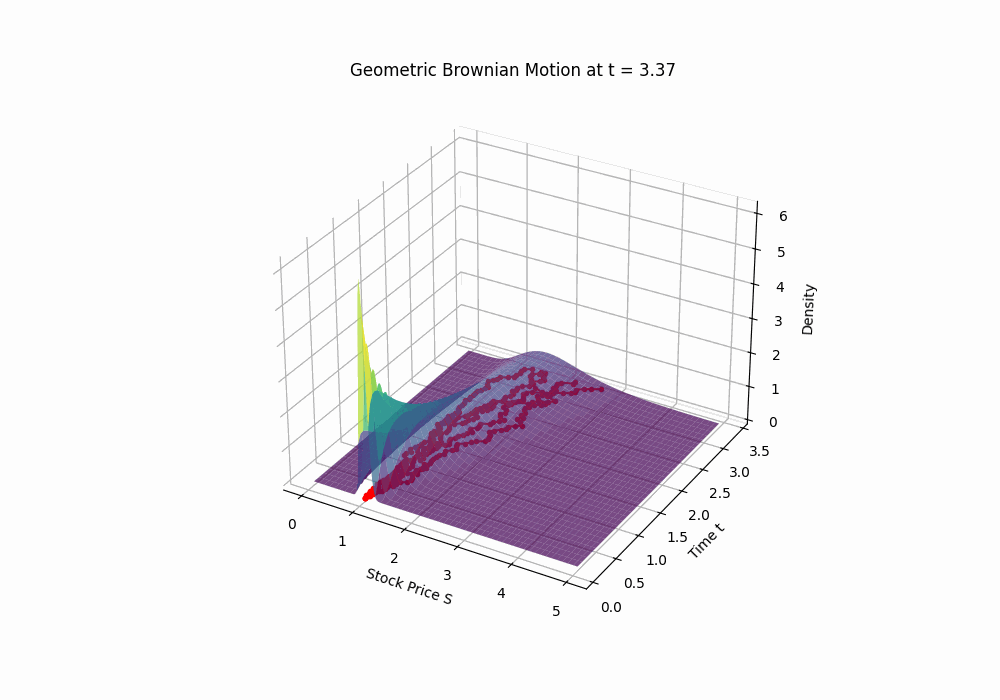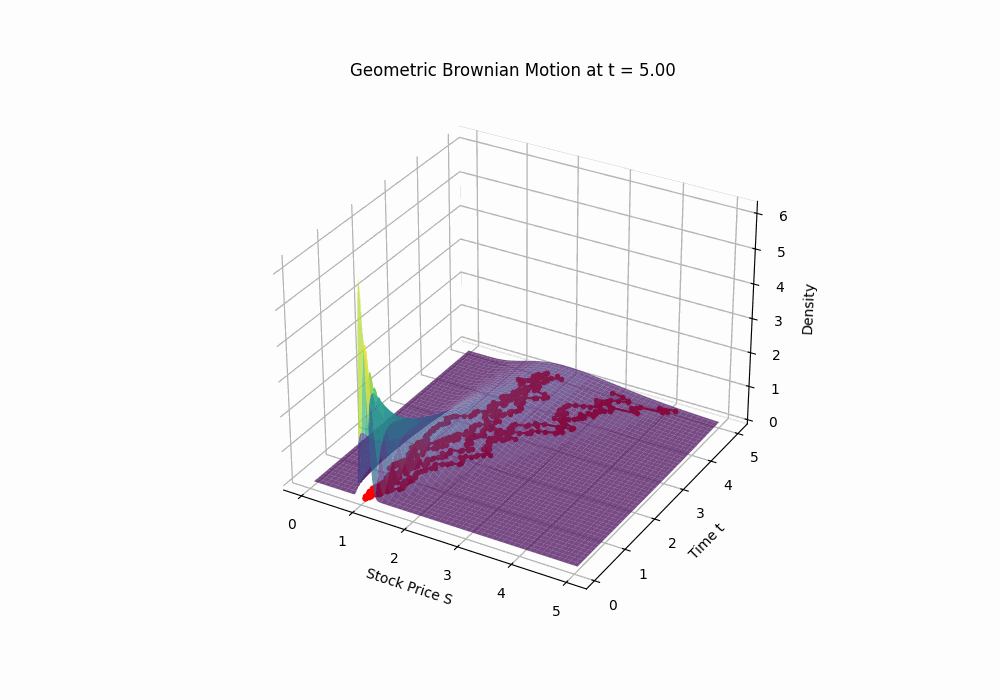 Code 3D animation: Geometric Brownian Motion drifting over time
Code 3D animation: Geometric Brownian Motion drifting over time
Beyond Analytics
Analytical solutions like GBM’s are exceptions. Most SDEs require numerical simulation (e.g., stepping \(X(t + \Delta t) = X(t) + \mu \Delta t + \sigma \sqrt{\Delta t} \, N(0, 1)\)) or statistical analysis via equations like Fokker-Planck. See the appendix for simulation code.
6. Stratonovich Calculus
Recall Itô’s lemma:
That second derivative term is pretty annoying to deal with in calculations. Is there a way we can simplify it to the familiar chain rule in regular calculus?
The answer is yes, and it’s called Stratonovich calculus. Let’s explore a bit. First, the deterministic part clearly satisfies the regular chain rule, since we can directly apply it using linearity. The trouble arises in the stochastic part, which we need to analyze. This means we only need to consider a function \(f(X(t))\).
Remember, for the Itô form, we chose to define the integral by choosing the left endpoint of each interval. In other words, it is this stochastic part that will vary. To delete this second order term, we need to somehow absorb it into the stochastic part by defining some Stratonovich differential, typically denoted by \(\circ dW\).
Going back to our Riemann sum definitions, our degrees of freedom lie in the choice of the evaluation point for each interval:
where \(\lambda \in [0,1]\) is a constant that linearly interpolates between the left and right endpoints of each interval giving a corresponding differential \(\diamond dW\), and \(\Delta X(t_i,t_{i+1}):=X(t_{i+1})-X(t_i)\).
In the deterministic case, since we always have \(O(dX^2) \to 0\), it doesn’t matter where we choose the evaluation point. However, in the stochastic case, remember that \(O(dW^2) \to O(dt)\), so we need a more careful choice of evaluation point.
Mathematically, our goal is to define a new stochastic integral that preserves the standard chain rule:
In the limiting discrete form, let’s try setting every term equal to each other:
In other words, our newly defined differential should result in the derivative being a linear approximation of the original function instead of quadratic:
But watch what happens as we take the Taylor expansion on both sides about \(X\) (recalling that \(o(\Delta X^2)\to 0\)):
Comparing coefficients, we wish to set \(\lambda = 1/2\) to preserve the chain rule. So Stratonovich integrals are defined by the midpoint evaluation rule:
Conversion Formula between Itô and Stratonovich
There is a formula to convert the Stratonovich differential into a corresponding Itô SDE that depends on the Itô differential as well as the volatility function \(\sigma\).
Recall that Itô’s lemma states that for \(dX = a dt + b dW\):
In parallel, we defined Stratonovich’s chain rule to satisfy for \(dX = \tilde a dt + \tilde b \circ dW\):
Hence, between Itô and Stratonovich SDEs, we have in both cases that the differential is scaled by the volatility function of \(X\) and \(f_X\), but the drift function changes. Let’s find a conversion formula between the two.
Suppose we have:
Then, our objective is to find \(\tilde a\) in terms of \(a\).
Recall from the integral definition that \(b(X) \circ dW = b(X+\frac{1}{2}dX) dW\). If we Taylor expand around \(X\), we have:
Now, if we plug in \(dX=a dt + b dW\), the first term vanishes, leaving \(b_X b \frac{1}{2}dW^2 \sim \frac{1}{2}b_X b dt\) (where the arguments \(X\) are left implicit).
Hence:
Applications of Stratonovich Calculus
Stratonovich calculus, with its midpoint evaluation rule, adjusts how we handle stochastic integrals compared to Itô’s left-endpoint approach. This shift makes it valuable in certain fields where its properties align with physical systems or simplify calculations. Below are some practical applications, each with a concrete mathematical example.
Physics with Multiplicative Noise: In physical systems, noise often scales with the state—like a particle in a fluid where random kicks depend on its position. Consider a damped oscillator with position \(X(t)\) under state-dependent noise:
\[ dX = -k X \, dt + \sigma X \circ dW \]Here, \(k > 0\) is the damping constant, \(\sigma\) is the noise strength, and \(\circ dW\) denotes the Stratonovich differential. Using Stratonovich’s chain rule, for \(f(X) = \ln X\):
\[ d(\ln X) = \frac{1}{X} (-k X \, dt + \sigma X \circ dW) = -k \, dt + \sigma \circ dW \]This integrates to \(X(t) = X(0) e^{-kt + \sigma W(t)}\), matching the expected exponential decay with noise. Stratonovich fits here because it preserves symmetries in continuous physical processes, unlike Itô, which adds a \(\frac{1}{2} \sigma^2 X \, dt\) drift term.
Wong-Zakai Theorem and Smooth Noise: Real-world noise isn’t perfectly white (uncorrelated like \(dW\))—it’s often smoother. The Wong-Zakai theorem shows that approximating smooth noise (e.g., \(\eta(t)\) with correlation time \(\epsilon\)) as \(\epsilon \to 0\) yields a Stratonovich SDE. Take a simple system:
\[ \dot{x} = a x + b x \eta(t) \]As \(\eta(t) \to\) white noise, this becomes \(dX = a X \, dt + b X \circ dW\). In Stratonovich form, the solution is \(X(t) = X(0) e^{a t + b W(t)}\). This is useful in engineering, like modeling voltage in a circuit with thermal fluctuations, where noise has slight smoothness.
Stochastic Control: In control problems, Stratonovich can simplify dynamics under feedback. Consider a system with control input \(u(t)\) and noise:
\[ dX = (a X + u) \, dt + \sigma X \circ dW \]For \(f(X) = X^2\), the Stratonovich rule gives:
\[ d(X^2) = 2X (a X + u) \, dt + 2X \cdot \sigma X \circ dW = (2a X^2 + 2X u) \, dt + 2\sigma X^2 \circ dW \]The lack of a second-derivative term (unlike Itô’s \(+ \sigma^2 X^2 dt\)) aligns with classical control intuition, making it easier to design \(u(t)\) for, say, stabilizing a noisy pendulum or a drone in wind.
Biological Diffusion: In biology, noise can depend on spatial gradients, like protein diffusion across a cell. Model this as:
\[ dX = \mu \, dt + \sigma(X) \circ dW, \quad \sigma(X) = \sqrt{2D (1 + k X^2)} \]where \(D\) is diffusivity and \(k\) adjusts noise with position. Stratonovich ensures the diffusion term reflects physical conservation laws, matching experimental data in systems like bacterial motility better than Itô, which alters the drift.
Numerical Stability: For simulations, Stratonovich pairs well with midpoint methods. Take \(dX = -a X \, dt + \sigma \circ dW\). A Stratonovich discretization might use:
\[ X_{n+1} = X_n - a \left(\frac{X_n + X_{n+1}}{2}\right) \Delta t + \sigma \Delta W_n \]This implicit scheme leverages the midpoint rule, reducing numerical artifacts in models like chemical kinetics compared to Itô’s explicit steps.
The choice between Stratonovich and Itô depends on context. Stratonovich suits systems where noise is tied to physical continuity or symmetry, while Itô dominates in finance for its non-anticipating properties. The conversion \(a = \tilde{a} + \frac{1}{2} b b_X\) lets you switch forms as needed.
Appendix
A.0. Further Reading
- An Intuitive Introduction For Understanding and Solving Stochastic Differential Equations - Chris Rackauckas (2017)
- Stochastic analysis - Paul Bourgade (2010)
- AN INTRODUCTION TO STOCHASTIC DIFFERENTIAL EQUATIONS VERSION 1.2 - Lawrence C. Evans (2013)
- Stochastic differential equations An introduction with applications - Bernt K. Øksendal (2003)
- Wikipedia: Stochastic calculus
- Wikipedia: Stochastic differential equation
A.1. Notation
Here is a list of notation used in this document:
- \(\binom{n}{k}=\frac{n!}{k!(n-k)!}\) is the binomial coefficient
- \(X: \Omega \to \mathbb{R}\) is a random variable from a sample space \(\Omega\) to a real number
- \(P(A)\) is the probability of event \(A\)
- \(E[X]=\int_{\omega \in \Omega} X(\omega) dP(\omega)\) is the expected value of \(X\)
- \(N(\mu, \sigma^2)\) is a normal distribution with mean \(\mu\) and variance \(\sigma^2\)
- \(W(t)\) is the position of a Brownian motion at time \(t\)
- \(\Delta W(t_1,t_2)\) is the displacement of a Brownian motion from time \(t_1\) to time \(t_2\)
- \(dt\) is an infinitesimal time increment
- \(dW := \Delta W(t,t+dt)\) is an infinitesimal increment of Brownian motion over time
- \((dW)^2 \sim dt\) denotes that \((dW^2) = dt + o(dt)\) where \(\lim_{t \to 0} \frac{o(dt)}{dt} = 0\), such that \((dW)^2\) is asymptotically equal to \(dt\) in the mean-square limit:
- \(f_t:=\frac{\partial f}{\partial t}\) is the partial derivative of \(f\) with respect to \(t\)
- \(f_xx:=\frac{\partial^2 f}{\partial x^2}\) is the second order partial derivative of \(f\) with respect to \(x\)
B.1. Python code for binomial plots
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
importnumpyasnpimportmatplotlib.pyplotaspltfromscipy.statsimportbinomn_values=[5,10,25,50,100]p=0.5# Individual plots
forninn_values:k=np.arange(0,n+1)positions=2*k-nprobs=binom.pmf(k,n,p)plt.figure(figsize=(6,4))plt.bar(positions,probs,width=1.0,color='skyblue',edgecolor='black')plt.title(f'n = {n}')plt.xlabel('Position (# wins - # losses)')plt.ylabel('Probability')plt.ylim(0,max(probs)*1.2)plt.savefig(f'random_walk_n_{n}.png',dpi=300,bbox_inches='tight')plt.close()# Combined plot
fig,axes=plt.subplots(5,1,figsize=(8,12),sharex=True)fori,ninenumerate(n_values):k=np.arange(0,n+1)positions=2*k-nprobs=binom.pmf(k,n,p)axes[i].bar(positions,probs,width=1.0,color='skyblue',edgecolor='black')axes[i].set_title(f'n = {n}')axes[i].set_ylabel('Probability')axes[i].set_ylim(0,max(probs)*1.2)axes[-1].set_xlabel('Position (# wins - # losses)')plt.tight_layout()plt.savefig('random_walk_combined.png',dpi=300,bbox_inches='tight')plt.close()
B2. Python Code for Brownian Motion Plot
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
importnumpyasnpimportmatplotlib.pyplotasplt# Simulate Brownian motion
np.random.seed(42)t=np.linspace(0,1,1000)# Time from 0 to 1
dt=t[1]-t[0]dW=np.sqrt(dt)*np.random.normal(0,1,size=len(t)-1)# Increments
W=np.concatenate([[0],np.cumsum(dW)])# Cumulative sum starts at 0
# Plot
plt.plot(t,W)plt.title("Sample Brownian Motion Path")plt.xlabel("Time t")plt.ylabel("W(t)")plt.grid(True)plt.show()
B3. Python Code for Basic SDE Simulation
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
importnumpyasnpimportmatplotlib.pyplotasplt# Simulate simple SDE: dX = mu dt + sigma dW
np.random.seed(42)T=1.0N=1000dt=T/Nt=np.linspace(0,T,N+1)mu,sigma=1.0,0.5X=np.zeros(N+1)foriinrange(N):dW=np.sqrt(dt)*np.random.normal(0,1)X[i+1]=X[i]+mu*dt+sigma*dWplt.plot(t,X,label=f"μ={mu}, σ={sigma}")plt.title("Sample Path of dX = μ dt + σ dW")plt.xlabel("Time t")plt.ylabel("X(t)")plt.legend()plt.grid(True)plt.show()
B4. Python Code for Geometric Brownian Motion Simulation
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
importnumpyasnpimportmatplotlib.pyplotasplt# Simulate simple SDE: dX = mu dt + sigma dW
np.random.seed(42)# Simulate Geometric Brownian Motion (exact solution)
T_gbm=10.0# Longer time to show exponential nature
N_gbm=1000t_gbm=np.linspace(0,T_gbm,N_gbm+1)S0=100.0# Initial stock price
mu,sigma=0.15,0.2# Slightly larger for visibility
S=S0*np.exp((mu-0.5*sigma**2)*t_gbm+sigma*np.sqrt(t_gbm)*np.random.normal(0,1,N_gbm+1))plt.figure(figsize=(8,4))plt.plot(t_gbm,S,label=f"μ={mu}, σ={sigma}")plt.title("Sample Path: Geometric Brownian Motion")plt.xlabel("Time t")plt.ylabel("S(t)")plt.legend()plt.grid(True)plt.savefig("gbm_path.png",dpi=300,bbox_inches="tight")plt.show()
B5. LaTeX Code for Tikz Diagram of Paths in Pascal’s Triangle
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
\documentclass{standalone}\usepackage{tikz}\begin{document}\begin{tikzpicture}[scale=0.8]
% Add a white background rectangle\fill[white] (-12, 1) rectangle (10, -5);
% Row labels (only once, to the left of the first diagram)\node[align=right] at (-11, 0) {Row 0};
\node[align=right] at (-11, -1) {Row 1};
\node[align=right] at (-11, -2) {Row 2};
\node[align=right] at (-11, -3) {Row 3};
% Diagram 1: Path RRL\node at (-6, 0) {1}; % Row 0\node at (-7, -1) {1}; % Row 1\node at (-5, -1) {1};
\node at (-8, -2) {1}; % Row 2\node at (-6, -2) {2};
\node at (-4, -2) {1};
\node at (-9, -3) {1}; % Row 3\node at (-7, -3) {3};
\node at (-5, -3) {3};
\node at (-3, -3) {1};
\draw[->, red, thick] (-6, 0) -- (-5, -1) -- (-4, -2) -- (-5, -3); % RRL\node at (-6, -4) {Right-Right-Left};
% Diagram 2: Path RLR\node at (0, 0) {1}; % Row 0\node at (-1, -1) {1}; % Row 1\node at (1, -1) {1};
\node at (-2, -2) {1}; % Row 2\node at (0, -2) {2};
\node at (2, -2) {1};
\node at (-3, -3) {1}; % Row 3\node at (-1, -3) {3};
\node at (1, -3) {3};
\node at (3, -3) {1};
\draw[->, blue, thick] (0, 0) -- (1, -1) -- (0, -2) -- (1, -3); % RLR\node at (0, -4) {Right-Left-Right};
% Diagram 3: Path LRR\node at (6, 0) {1}; % Row 0\node at (5, -1) {1}; % Row 1\node at (7, -1) {1};
\node at (4, -2) {1}; % Row 2\node at (6, -2) {2};
\node at (8, -2) {1};
\node at (3, -3) {1}; % Row 3\node at (5, -3) {3};
\node at (7, -3) {3};
\node at (9, -3) {1};
\draw[->, green, thick] (6, 0) -- (5, -1) -- (6, -2) -- (7, -3); % LRR\node at (6, -4) {Left-Right-Right};
\end{tikzpicture}\end{document}
3D Visualizations
C1. 3D Plot of Discrete Random Walks
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
importnumpyasnpimportmatplotlib.pyplotaspltfrommpl_toolkits.mplot3dimportAxes3D# for 3D plotting
importimageio.v3asimageio# using modern imageio v3 API
importosfromscipy.specialimportcombfromscipy.statsimportnorm# Create a directory for frames
os.makedirs('gif_frames',exist_ok=True)##############################################
# Part 1: Discrete Binomial Random Walk (N = 15)
##############################################
N=15# total number of steps (kept small for clear discreteness)
num_sample_paths=5# number of sample paths to overlay
# Simulate a few discrete random walk sample paths
sample_paths=[]foriinrange(num_sample_paths):steps=np.random.choice([-1,1],size=N)path=np.concatenate(([0],np.cumsum(steps)))sample_paths.append(path)sample_paths=np.array(sample_paths)# shape: (num_sample_paths, N+1)
frames=[]fort_stepinrange(N+1):fig=plt.figure(figsize=(10,7))ax=fig.add_subplot(111,projection='3d')# For each discrete time slice up to the current time, plot the PMF
fortinrange(t_step+1):# For a random walk starting at 0, possible positions are -t, -t+2, ..., t
x_values=np.arange(-t,t+1,2)ift==0:p_values=np.array([1.0])else:# k = (x + t)/2 gives the number of +1 steps
k=(x_values+t)//2p_values=comb(t,k)*(0.5**t)# Plot the discrete PMF as blue markers (and connect them with a line)
ax.scatter(x_values,[t]*len(x_values),p_values,color='blue',s=50)ax.plot(x_values,[t]*len(x_values),p_values,color='blue',alpha=0.5)# Overlay the sample random walk paths (projected at z=0)
forspinsample_paths:ax.plot(sp[:t_step+1],np.arange(t_step+1),np.zeros(t_step+1),'r-o',markersize=5,label='Sample Path'ift_step==0else"")ax.set_xlabel('Position (x)')ax.set_ylabel('Time (steps)')ax.set_zlabel('Probability')ax.set_title(f'Discrete Binomial Random Walk: Step {t_step}')ax.set_zlim(0,1.0)ax.view_init(elev=30,azim=-60)frame_path=f'gif_frames/discrete_binomial_{t_step:02d}.png'plt.savefig(frame_path)plt.close()frames.append(imageio.imread(frame_path))# Compute per-frame durations: 0.25 sec for all frames except the last one (2 sec)
durations=[0.25]*(len(frames)-1)+[2.0]# Write the GIF with variable durations and infinite looping
imageio.imwrite('discrete_binomial.gif',frames,duration=durations,loop=0)##############################################
# Part 2: Discrete Random Walk Normalizing (N = 50)
##############################################
N=50# total number of steps (increased to show gradual convergence)
num_sample_paths=5# number of sample paths to overlay
# Simulate a few discrete random walk sample paths
sample_paths=[]foriinrange(num_sample_paths):steps=np.random.choice([-1,1],size=N)path=np.concatenate(([0],np.cumsum(steps)))sample_paths.append(path)sample_paths=np.array(sample_paths)# shape: (num_sample_paths, N+1)
frames=[]fort_stepinrange(N+1):fig=plt.figure(figsize=(10,7))ax=fig.add_subplot(111,projection='3d')# Plot the PMFs for all time slices from 0 to the current step
fortinrange(t_step+1):# For a random walk starting at 0, possible positions are -t, -t+2, ..., t
x_values=np.arange(-t,t+1,2)ift==0:p_values=np.array([1.0])else:# For each x, number of +1 steps is (x+t)/2
k=(x_values+t)//2p_values=comb(t,k)*(0.5**t)# Plot the discrete PMF as blue markers and lines
ax.scatter(x_values,[t]*len(x_values),p_values,color='blue',s=50)ax.plot(x_values,[t]*len(x_values),p_values,color='blue',alpha=0.5)# For the current time slice, overlay the normal approximation in red
ift==t_stepandt>0:x_cont=np.linspace(-t,t,200)normal_pdf=norm.pdf(x_cont,0,np.sqrt(t))ax.plot(x_cont,[t]*len(x_cont),normal_pdf,'r-',linewidth=2,label='Normal Approx.')# Overlay the sample random walk paths (projected along the z=0 plane)
forspinsample_paths:ax.plot(sp[:t_step+1],np.arange(t_step+1),np.zeros(t_step+1),'g-o',markersize=5,label='Sample Path'ift_step==0else"")ax.set_xlabel('Position (x)')ax.set_ylabel('Time (steps)')ax.set_zlabel('Probability')ax.set_title(f'Discrete Binomial Random Walk at Step {t_step}')ax.set_zlim(0,1.0)ax.view_init(elev=30,azim=-60)frame_path=f'gif_frames/discrete_binomial_{t_step:02d}.png'plt.savefig(frame_path)plt.close()frames.append(imageio.imread(frame_path))# Compute per-frame durations: 0.25 sec for all frames except the last one (2 sec)
durations=[0.25]*(len(frames)-1)+[2.0]# Write the GIF with variable durations and infinite looping
imageio.imwrite('discrete_binomial_normalizing.gif',frames,duration=durations,loop=0)
C2. 3D Animation of Brownian Motion
Normal distribution sweeping and evolving across time according Brownian motion
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
importnumpyasnpimportmatplotlib.pyplotaspltfrommpl_toolkits.mplot3dimportAxes3D# for 3D plotting
fromscipy.statsimportnormimportimageio.v3asimageio# using modern API
importosos.makedirs('gif_frames',exist_ok=True)# Parameters for continuous Brownian motion
num_frames=100# more frames for smoother animation
t_values=np.linspace(0.1,5,num_frames)x=np.linspace(-5,5,200)# increased resolution
num_sample_paths=5sample_paths=np.zeros((num_sample_paths,len(t_values)))dt_cont=t_values[1]-t_values[0]foriinrange(num_sample_paths):increments=np.random.normal(0,np.sqrt(dt_cont),size=len(t_values)-1)sample_paths[i,1:]=np.cumsum(increments)frames=[]fori,tinenumerate(t_values):fig=plt.figure(figsize=(10,7))ax=fig.add_subplot(111,projection='3d')mask=t_values<=tT_sub,X_sub=np.meshgrid(t_values[mask],x)P_sub=(1/np.sqrt(2*np.pi*T_sub))*np.exp(-X_sub**2/(2*T_sub))ax.plot_surface(X_sub,T_sub,P_sub,cmap='viridis',alpha=0.7,edgecolor='none')forspinsample_paths:ax.plot(sp[:i+1],t_values[:i+1],np.zeros(i+1),'r-',marker='o',markersize=3)ax.set_xlabel('Position (x)')ax.set_ylabel('Time (t)')ax.set_zlabel('Density')ax.set_title(f'Continuous Brownian Motion at t = {t:.2f}')ax.view_init(elev=30,azim=-60)frame_path=f'gif_frames/continuous_3d_smooth_t_{t:.2f}.png'plt.savefig(frame_path)plt.close()frames.append(imageio.imread(frame_path))imageio.imwrite('continuous_brownian_3d_smooth.gif',frames,duration=0.1,loop=0)
C3. 3D Animation of Geometric Brownian Motion
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
importnumpyasnpimportmatplotlib.pyplotaspltfrommpl_toolkits.mplot3dimportAxes3D# for 3D plotting
importimageio.v3asimageio# modern API
importosos.makedirs('gif_frames',exist_ok=True)# Parameters for geometric Brownian motion (GBM)
S0=1.0# initial stock price
mu=0.2# drift rate (increased for noticeable drift)
sigma=0.2# volatility
num_frames=100t_values=np.linspace(0.1,5,num_frames)# avoid t=0 to prevent singularity in density
S_range=np.linspace(0.01,5,200)# price range
# Simulate GBM sample paths
num_sample_paths=5sample_paths=np.zeros((num_sample_paths,len(t_values)))dt=t_values[1]-t_values[0]foriinrange(num_sample_paths):increments=np.random.normal(0,np.sqrt(dt),size=len(t_values)-1)W=np.concatenate(([0],np.cumsum(increments)))sample_paths[i]=S0*np.exp((mu-0.5*sigma**2)*t_values+sigma*W)frames=[]fori,tinenumerate(t_values):fig=plt.figure(figsize=(10,7))ax=fig.add_subplot(111,projection='3d')mask=t_values<=tT_sub,S_sub=np.meshgrid(t_values[mask],S_range)P_sub=(1/(S_sub*sigma*np.sqrt(2*np.pi*T_sub)))* \
np.exp(-(np.log(S_sub/S0)-(mu-0.5*sigma**2)*T_sub)**2/(2*sigma**2*T_sub))ax.plot_surface(S_sub,T_sub,P_sub,cmap='viridis',alpha=0.7,edgecolor='none')forspinsample_paths:ax.plot(sp[:i+1],t_values[:i+1],np.zeros(i+1),'r-',marker='o',markersize=3)ax.set_xlabel('Stock Price S')ax.set_ylabel('Time t')ax.set_zlabel('Density')ax.set_title(f'Geometric Brownian Motion at t = {t:.2f}')ax.view_init(elev=30,azim=-60)frame_path=f'gif_frames/geometric_brownian_drifted_3d_t_{t:.2f}.png'plt.savefig(frame_path)plt.close()frames.append(imageio.imread(frame_path))imageio.imwrite('geometric_brownian_drifted_3d.gif',frames,duration=0.1)
C4. Python Code for Normal Distribution Approximation by Random Walks
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
importnumpyasnpimportmatplotlib.pyplotaspltfromscipy.statsimportnormimportimageio.v3asimageio# modern ImageIO v3 API
importosfromscipy.specialimportcomb# Create a directory for frames
os.makedirs('gif_frames',exist_ok=True)# 1. Continuous Brownian Motion with Sample Paths
# Define time values and x range for density
t_values=np.linspace(0.1,5,50)# Times from 0.1 to 5
x=np.linspace(-5,5,100)# Range of x values
# Simulate a few sample Brownian motion paths
num_sample_paths=5dt_cont=t_values[1]-t_values[0]# constant time step (~0.1)
sample_paths=np.zeros((num_sample_paths,len(t_values)))sample_paths[:,0]=0increments=np.random.normal(0,np.sqrt(dt_cont),size=(num_sample_paths,len(t_values)-1))sample_paths[:,1:]=np.cumsum(increments,axis=1)frames=[]fori,tinenumerate(t_values):p=(1/np.sqrt(2*np.pi*t))*np.exp(-x**2/(2*t))plt.figure(figsize=(12,4))plt.subplot(1,2,1)plt.plot(x,p,'b-',label=f't = {t:.2f}')plt.title('Brownian Motion Distribution')plt.xlabel('x')plt.ylabel('Density p(x,t)')plt.ylim(0,0.8)plt.legend()plt.grid(True)plt.subplot(1,2,2)forspinsample_paths:plt.plot(t_values[:i+1],sp[:i+1],'-o',markersize=3)plt.title('Sample Brownian Paths')plt.xlabel('Time')plt.ylabel('Position')plt.xlim(0,5)plt.grid(True)frame_path=f'gif_frames/continuous_t_{t:.2f}.png'plt.tight_layout()plt.savefig(frame_path)plt.close()frames.append(imageio.imread(frame_path))# Save the continuous Brownian motion GIF
# (duration in seconds per frame; adjust as desired)
imageio.imwrite('continuous_brownian.gif',frames,duration=0.1)# 2. Discrete Random Walk with Sample Paths
defsimulate_random_walk(dt,T,num_paths):"""Simulate random walk paths with step size sqrt(dt)."""n_steps=int(T/dt)positions=np.zeros((num_paths,n_steps+1))foriinrange(num_paths):increments=np.random.choice([-1,1],size=n_steps)*np.sqrt(dt)positions[i,1:]=np.cumsum(increments)returnpositionsdt=0.01# Step size
T=5.0# Total time
num_paths=10000# For histogram
times=np.arange(0,T+dt,dt)positions=simulate_random_walk(dt,T,num_paths)sample_indices=np.arange(5)frames=[]fori,tinenumerate(times):ifi%10==0:# Use every 10th frame for the GIF
current_positions=positions[:,i]x_vals=np.linspace(-5,5,100)p_theoretical=norm.pdf(x_vals,0,np.sqrt(t)ift>0else1e-5)plt.figure(figsize=(12,4))plt.subplot(1,2,1)plt.hist(current_positions,bins=50,density=True,alpha=0.6,label=f't = {t:.2f}')plt.plot(x_vals,p_theoretical,'r-',label='N(0,t)')plt.title('Discrete Random Walk Distribution')plt.xlabel('Position')plt.ylabel('Density')plt.ylim(0,0.8)plt.legend()plt.grid(True)plt.subplot(1,2,2)foridxinsample_indices:plt.plot(times[:i+1],positions[idx,:i+1],'-o',markersize=3)plt.title('Sample Random Walk Paths')plt.xlabel('Time')plt.ylabel('Position')plt.xlim(0,T)plt.grid(True)frame_path=f'gif_frames/discrete_t_{t:.2f}.png'plt.tight_layout()plt.savefig(frame_path)plt.close()frames.append(imageio.imread(frame_path))# Save the discrete random walk GIF with infinite looping
imageio.imwrite('discrete_random_walk.gif',frames,duration=0.1,loop=0)